I did post recently, from which I shall now quote:
Two minute to 30 minute horizon: Mean reversion works, and is most effective at the 4-8 minute horizon from a predictive perspective; although from a Sharpe Ratio angle it's likely the benefits of speeding up to a two minute trade window would overcome the slight loss in predictability. There is no possibility that you would be able to overcome trading costs unless you were passively filled, with all that implies... Automating trading strategies at this latency - as you would inevitably want to do - requires some careful handling (although I guess consistently profitable manual scalpers do exist that aren't just roleplaying instagram content creators, I've never met one). Fast mean reversion is also of course a negatively skewed strategy so you will need deep pockets to cope with sharp drawdowns. Trade mean reversion but proceed with great care.
Am I the only person who read that and thought.... well if anyone can build an automated scalping bot... surely I can?
To be precise something with a horizon of somewhere around the 4-8 minute mark, but we'd happily go a bit slower (though not too much, lest we hit the dreaded region of mean reversion), or even a bit quicker.
In fact I already have the technology to build one (at least in futures). There's a piece of code in my open source trading system called the (order) stack handler. This code exists to manage the execution of my trades, and implements my simple trading algo, which means it can do stuff like this:
- get streaming prices from interactive brokers
- place, modify and cancel orders, and check their status with IB
- get fills and write them to a database so I can keep track of performance
- work out my current position and check it is synched with IB
I'll need to do a little extra coding and configuration. For example, I will probably inherit from this class to create my little scalping bot. I will also want to partition my trading universe into the scalped instruments, and the rest of my portfolio (it would be too risky to do both on a given market; and my dynamic optimisation means removing a few instruments from my main system won't cause too much of a headache).
All that leaves then is the "easy" job of creating the actual algo that this bot will run... and doing so profitably.
Some messy python (no psystemtrade required), here, and an sketchy implementation in psystemtrade here.
Some initial thoughts
I'm going to begin with a bit of a brain dump:
So the basic idea is that we start the day flat, and from the current price we set symmetric up and down bracket limit orders. To simplify things, we'll assume those orders are for a fixed number of contracts (to be determined); most likely one but could be more. Also to be determined are the width of those limit orders.
Unlike the (now discredited) slower mean reversion strategy in my fourth book, we won't use any kind of slow trend overlay here. We're going to be trading so darn quick that the underlying trend will be completely irrelevant. That means we're going to need some kind of stop loss.
If I describe my scalper as a state machine then, it will have a number of states. Let's first assume we make money on a buy.
A: Start: no positions or orders
- Place initial bracket order
B: Ready: buy limit and sell limit
- Buy limit order taken out
C: Long and unprotected: (existing) sell limit order at a profit
- Place sell stop loss below current level
D: Long and protected: (existing) sell limit order at a profit (higher) and sell stop loss order (lower)
- Hit sell limit profit order
E: Flat and unbalanced: sell stop loss order
- Cancel sell stop loss order
A: No positions or orders
Or if you prefer a nice picture:
Lines are orders, black is price, then green because we are long, then black again when we are flat. Red lines are sell order, dotted line is stop loss, green line is buy order.
What happens next: is we reset, and place bracket orders around the current price which is assumed to be the current equilibrium price. Note: if we didn't assume it was the current equilibrium we would have the opportunity to leave our stop loss orders in place. But that also assumes we're going to use explicit stops, which is a design decision to leave for now.
The other profitable path we can take is:
B: Ready: buy limit and sell limit
- Sell limit order taken out
F: Short and unprotected: (existing) buy limit order at a profit
- Place buy stop loss above current level
G: Short and protected: (existing) buy limit order at a profit (lower) and buy stop loss order (higher)
- Hit buy limit profit order
H: Flat and unbalanced: buy stop loss order
- Cancel buy stop loss order
A: No positions or orders
Now what if things go wrong?
D: Long and protected: (existing) sell limit order at a profit (higher) and sell stop loss order (lower)
- Hit sell limit stop loss
J: Flat and unbalanced: sell limit order
- Cancel sell limit order
A: No positions or orders
Alternatively:
G: Short and protected: (existing) buy limit order at a profit (lower) and buy stop loss order (higher)
- Hit buy stop loss limit
K: Flat and unbalanced: buy limit order
- Cancel buy limit order
A: No positions or orders
That's a neat ten states to consider. Of course with faster trading there is the opportunity for async events which will effectively result in some other states occuring, but we'll return to that later. Finally, we're probably going to want to have a 'soft close' time before the end of the day beyond which we wouldn't reopen new positions, and then a 'hard close' time when we would close our existing position irrespective of p&l.
It's clear that the profitability, risk, and the average holding period of this bad boy are going to depend on what proportion of our trades are profitable, and hence on some parameters we need to set:
- position size
- initial bracket width
- distance to stop loss
... some numbers we need to know:
- contract multiplier and FX
- commissions and exchange fees
- the cost of cancelling orders
... and also on on some values we need to estimate:
- volatility (we'd probably need a short warm up period to establish what that is)
- likely autocorrelation in prices
Note: We're also going to have to consider tick size, which we need to round our limit orders, but also in the limit will result in a minimum bracket width of two ticks (assuming that would still be a profitable thing to do).
Further possible refinements to the system could be to avoid trading if volatility is very high, or is in a period of adjustment to a higher level (which depending on time scale can basically mean the same thing). We could also throw in a daily stop loss on the scalper, if it loses more than X we stop for the day as we're just 'not feeling it'.
Another implementation detail that springs to mind is how we handle futures rolls; since we hope to end the day flat this should be quite easy; we just need to make sure any rolls are done overnight and not trade if the system is in any kind of roll state (see 'tactics' chapter in AFTS and doc here).
Living in a world of OHLC
Now as you know I'm not a big fan of using OHLC bars in my trading strategies - I normally just use close prices. I associate using OHLC prices and creating candle stick charts with the sort of people who think Fibbonaci is a useful trading strategy, rather
than the in house restaurant at a london accountants office.
However OHLC do have something useful to gift us, which is the concept of the likely trading range over a given time period (the top and the bottom of a candle).
Let's call that range R, and it's simply the difference between the highest and lowest prices over some time horizon H (to be determined). We can look at the most recent time bucket, or take an average over multiple periods (a stable R could be a good indication of stable volatility which is a good thing for this strategy). So for example if we're looking at '5 minute bars' (I'll be honest it takes an effort to use this kind of language and not throw up), then we could look at the height of the last bar, or take a (weighted?) average over the last N bars.
Now to set our initial bracket limit orders. We're going to set them at (R/2)*F above and below the current price. Note that if F=1, we'll set a bracket range which is equal to R. Given we're assuming that R is constant and represents the expected trading range, we're probably not going to want to set F>=1. Smaller values of F mean we are capturing less of the spread, but we're exposed for less time. Note that setting a smaller F is equivalent to trading the same F on a smaller R, which would be a shorter horizon. So reducing F just does the same thing as reducing R. For simplicity then, we can set F to be some fixed value. I'm going to use F=0.75.
Finally, what about our stop losses? It probably makes sense to also scale them against R. Note that if we are putting on a stop loss we must already have a position on, which means the price has already moved by (R/2)*F. The remaining price "left" in the range is going to be (R/2)*(1-F); to put it another way versus the original 'starting' price we could set our stop loss at (R/2) on the appropriate side if we wanted to stop out at the extremes of the range. But maybe we want to allow ourselves some wriggle room, or set a stop closer to our original entry point. Let's set our stop at (R/2)*K from the original price, where K>F.
Note this means our (theoretical!!!) max loss on any trade is going to be (R/2)*(K-F). For example, if F=0.75 and K=1.25 (so we place our stops at the extreme of the range), then the most we can lose if we hit our stop precisely is R/4.
Back of the envelople p&l
We're now in a position to work out precisely what our p&l will be on winning trades, and roughly (because stop loss) on losing trades. Let's ignore currency effects and set the multiplier of the future to be M (the $ or otherwise value of a 1 point price move). Let's set commission to C and also assume that it costs C to cancel a trade (the guidance on trade cancelling cost in interactive brokers docs is vague, so best to be conservative). In fact it makes more sense to express C as a proportion of M, c.
Finally we assume we're going to use an explicit stop loss order rather than implicit which means paying a cancellation charge.
win, W = R*F*M - 3C = R*F*M - 3Mc = M(R*F - 3c)
loss, L = -(K-F)*M*R/2 - 3C = -M[(K-F)*R/2 + 3c)
I always prefer concrete examples. For the SPY micro, M=$5, C=$0.25, c=0.05 and let's assume for now that R=10. I'll also assume we stick to F=0.75 and K = 1.25. So our expected win is:
W = $5 * (10*0.75 - 3*0.05) = $36.75
L = -5*[(1.25 - 0.75)*10/2 +3*0.05] = -$13.25
Note that in the absence of transaction costs the ratio of W to L would be equal to 2F / (F-K) which in this case is equal to 3. Note also that the breakeven probability of a win for this to be a profitable system is L / (L-W) which would be 0.25 without costs, but actually comes out at around 0.265 with costs.
We can see that setting K will change the character of our trading system. The system above is likely to be quite positive skew (breakeven probability). If we were to make K smaller, then we'd have more wins but they are likely to be smaller, and we'd get closer to negative skew.
Introducing the speed limit
Readers of my books will know that I am keen on something called the 'speed limit'; the idea that we shouldn't pay too much of our expected return on costs. I recommend an absolute maximum of 1/3 of returns paid out on costs; in practice eg for my normal trading strategy I pay about 1% a year and hope to earn at least ten times on that.
On the same logic, I'm not sure I'd be especially happy with a strategy where I have to pay up half my profits in costs even on a winning trade. Let's suppose the fraction of gross profit I am happy to pay is L, then:
3Mc / R*F*M = L
R = 3c / LF
For example, if L was 0.1 (we only want to pay 10% of our costs), then the minimum R for F=0.75 on the S&P 500 with c=0.05 would be 3*.05 / (0.1 * 0.75) = 2
In practice this will put a floor on the horizon chosen to estimate R; if H is too short then R won't be big enough. The more volatile the market is, the shorter the horizon will be when R is sufficiently large. However we would want to be wary of a longer horizon, since that would push us towards a holding period where autocorrelation is likely to turn against us (getting up towards 30 minutes).
But as we will see later, this crude method significantly understimates the impact of costs as it ignores the cost of losing trades. In practice we can't really use the speed limit idea here.
Random thought: Setting H or setting R?
We can imagine two ways of running this system:
- We set R to be some fixed value. The trading horizon would then be implicit depending on the volatility of the market. Higher vol, shorter horizon. We might want to set some limits on the horizon (this implies we'll need some sensitivity analysis on the relationship between horizon and the ratio of R and vol). For example, if we go below a two minute horizon we're probably pushing the latency possibilities of the python/ib_insyc/IB execution stack, as well as going beyond the horizon analysed in the
arvix paper. If we go above a fifteen minute horizon, we're probably going to lose mean reversion again as in the arvix paper.
- We set the horizon H at some fixed value, and estimate R. We might want to set some limits on R - for example the speed limit mentioned above would put a lower limit on R.
In practice we can mix these approaches; for example estimating R at a given horizon at the start of each day (perhaps using yesterdays data, or a warm up period), and then keeping it fixed throughout the day; or maybe re-estimating once or twice intraday. We can also at this point perhaps do some optimisation on the best possible value of H; the period when we see the best autocorrelation.
Simulation
Right, shall we simulate this bad boy? Notice I don't say backtest. I don't have the data to backtest this. I'm going to assume, initially, very benign normal distribution returns that - less benign - has no autocorrelation.
Initially I'm going to use iid returns, which is conservative (because no autocorrelation) but also aggresive (no jumps or gaps in prices, or changes in volatility during the day). I'm also going to use zero costs and cancellation fees, and optimistically assume stop losses are filled at their given level. We're just going to try and get a feel for how changing the horizon, and K affect return distribution. I'm going to re-estimate R throughout the day with a fixed horizon, but given the underlying distribution is random this won't make a huge amount of difference.
The distribution is set up to look a bit like the S&P 500 micro future; I assume 20% annualised daily vol and then scale that down to an 8 hour day (so no overnight vol). That equates to 71.25 units of price of daily vol, assuming the current index level of ~5700. I will simulate one day of ten second price ticks, do this a bunch of times, and then see what happens. The other parameters are those for the S&P micro: contract multiplier $5, tick size $0.25, and I also use a single contract when trading.
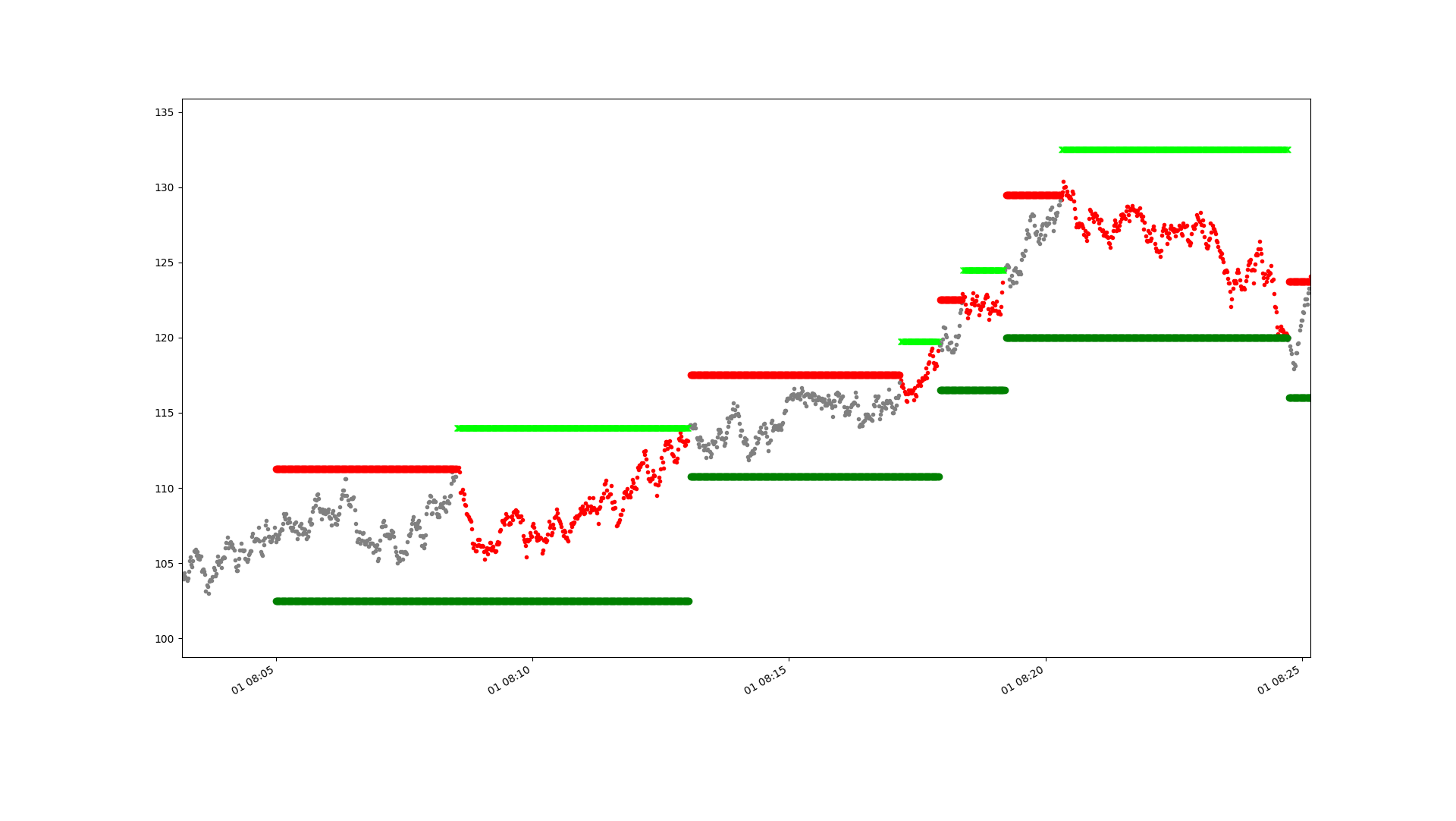
The simulations can be used to produce pretty plots like this which show what is going on quite nicely:
The price is in grey, or red when we are short, or green if long. The horizontal dark red and green lines are the initial take profit bracket orders. You can see we hit one early on and go short. The light green line is a buy stop loss (there are no sell stop losses in this plot as we're only ever short). You can see we hit that, so our initial trade fails. We then get two short lived losing trades, followed by a profitable trade near the end of the period when the price retraces from the red bracket entry down to the green take profit line.
Here's a distribution of 5000 days of simulation with a 5 minute horizon, and K=1.25 (with F=0.75):
Well it loses money, which isn't great. The loss is 0.4 Units of the daily risk on one contract (daily vol 71.25 multiplied by multiplier $5). And that's with zero costs and optimistic fills remember. Although there is a small point to make, which is that this isn't a true order book simulator. I only simulate a single price to avoid the complexity of modelling order arrival. In reality we'd gain a little bit from having limit orders in place in a situation where the mid price gets near but doesn't touch the limit order. Basically we can 'earn' the bid-ask bounce.
The distribution of daily returns is almost perfectly symettrical, obviously that wouldn't be true of the trade by trade distribution.
What happens if we set a tighter stop, say K=0.85?
Now we're seeing profits (0.36 daily risk units) AND some nice positive skew on the daily returns (which have a much lower standard deviation of about 0.40 daily risk units). Costs are likely to be higher though, and we'll check that shortly. Note we have a daily SR approaching 1.... which is obviously bonkers- it annualises to nearly 15!!! Incredible bearing in mind there is no autocorrelation in the price series at all here. But of course, no costs.
What happens if we increase the estimate period for R to 600 seconds (10 minutes), again with K=0.85:
Skew improves but returns don't. Of course, costs are likely to fall with a longer horizon.
An analysis of R and horizon
Bearing in mind we know what the vol of this market is (71.25 price units per day), how does the R measured at different horizons compare to that daily vol? Note this isn't affected by the stoploss or costs.
At 60 seconds, average R is 4.6, in daily vol units: 0.065
At 120 seconds, .... R in vol units: 0.10
At 240 seconds, ... R in vol units: 0.15
At 360 seconds, ... R in vol units: 0.19
At 480 seconds, ... R in vol units: 0.22
At 600 seconds, ... R in vol units: 0.25
At 900 seconds, ... R in vol units: 0.31
This doesn't quite grow at sqrt(T) eg T^0.5, but at something like T^0.59.
Footnote: even the smallest value of R here is greater than the minimum calculated earlier based on our speed limit. Of course that wouldn't be true for every market.
Now let's include costs in our analysis. I'm going to assume we pay $0.25 per contract, and the same to cancel, which is c=0.05 as a proportion of the $5 multiplier. In the following tables, the rows are values of H, and the columns are values of K. For each I run 5000 daily simulations and take the statistics of the distribution of daily returns.
First the average daily returns, normalised as a multiple of the daily $ risk on one contract (71.25 * M = $356.25 ). Note I haven't populated the entire table, as there is no point focusing on points which won't make any money (with the exception of those we've already looked at).
H / K 0.8 0.85 0.92 1.0 1.25
120 0.62 0.26 -0.16 -0.53 -1.08
240 0.37 0.09 -0.21 -0.44 -0.70
300 0.30 0.04 -0.22 -0.60
600 0.14 -0.04
900 0.07 -0.05 -0.25
Note we've already seen some of these values before pre-cost; H=300, K=1.25 was -0.4 (now -0.60), H=300, K=0.85 was 0.36 (now 0.044), and H=600, K=0.85 was 0.13 (now -0.04). So we lose about 0.2, 0.32 and 0.17 in daily risk units in costs. We lose more in costs if H is smaller (as we trade more often) and with a tighter stoploss (as we have more losing trades, and thus trade more often). To put it another way, we lose 1 - (0.044/0.36) = 78% of our gross returns to costs with H=300, K=0.85 (which is a darn sight more than the speed limit would like!).
Note: even with a 5000 point bootstrap there is some variability in these numbers; for example I ran the H=120/K=0.8 twice and on the other occasion got a mean of over 0.8.
Standard deviations, normalised as a multiple of the daily $ risk on one contract:
H / K 0.8 0.85 0.92 1.0 1.25
120 0.34 0.37 0.41 0.46 0.58
240 0.35 0.39 0.45 0.50 0.63
300 0.35 0.40 0.47 0.65
600 0.35 0.41
900 0.35 0.41 0.67
These are mostly driven by the stop; with longer lookbacks increasing it slightly but not by much.
Annualised daily SR:
H / K 0.8 0.85 0.92 1.0 1.25
120 28.8 11.4 -6.0 -17.7 -29.7
240 17.0 3.8 -7.7 -14.1 -17.7
300 13.9 1.77 -7.5 -14.6
600 6.3 -1.53
900 3.24 -1.98 -5.9
These numbers are... large. Both positive and negative.
Skew:
H / K 0.8 0.85 0.92 1.0 1.25
120 0.16 0.12 0.09 0.07 0.03
240 0.18 0.22 0.15 0.13 0.03
300 0.30 0.16 0.19 0.10
600 0.42 0.27
900 0.54 0.35 0.08
As we'd expect, tighter stop is better skew. But we also get positive skew from longer holding periods.
With more conservative fills
So it's simple, right, we should run a short horizon (say H=120) with a tight stop (say 0.8, which is only 0.05R away from the initial entry price). It does seem that a tight stop is the key to success; the SR is very sensitive to the stop increasing in size,
But it's perhaps worth examining what happens to the SR of such a system as we change our assumptions about costs and fills. With very tight stops, and short horizons, we are going to get lots more trades (so costs have a big impact), and hit many more stops; so the level at which we assume they are filled is critical. Remember above I've assumed that stops are hit at the exact level they are set at.
Z: Zero costs, stop loss filled at limit, take profit filled at limit
CL: Costs, stop loss filled at limit, take profit filled at limit
CP: Costs, stop loss filled at next price, take profit filled at limit
CLS: Costs, stop loss filled at limit + slippage, take profit filled at limit
CPS: Costs, stop loss filled at next price + slippage, take profit filled at limit
CLS2: Costs, stop loss filled at limit + slippage, take profit filled at limit - slippage
CPS2: Costs, stop loss filled at next price + slippage, take profit filled at limit - slippage
Two sided slippage (CSL2, CPS2)- means we assume we earn 1/2 a tick on take profit limit orders (assumes a 1 tick spread, which is configurable), and have to pay 1/2 a tick on stop losses (of which there will be many more with such tight stops). Essentially it's the approximation I use normally when backtesting, and tries to get us closer to a real order book. There's also a more pessimistic one sided version of these (CLS, CPS) where we only apply the negative slippage.
Here are the Sharpe Ratios, different strategies in columns (I've just gone for a selection of apparently profitable), different cost assumptions in rows (numbers are comparable with each other as used same random seed, but not comparable with those above):
H/K: 120/0.8 300/0.8 900/0.8 120/0.85 300/0.85
ZL: 48.6 23.9 7.5 29.6 10.4
CL: 28.9 14.1 3.2 11.9 2.5
CLS2: 32.2 15.4 3.7 16.5 4.1
CLS: 7.0 2.9 -1.7 -7.2 -6.2
CP: -120 -69 -35 -114 -59
CPS2: -115 -66 -34 -109 -56
CPS: -129 -75 -38 -123 -64
Well we know that zero costs (ZL) and costs with stop losses being hit exactly (CL) are probably a pipe dream, so then it's a question of which of the other five options gets closest to the messy reality of a real life order book as far as executing the stop loss orders goes. Clearly using the next price(CP*) is an absolute killer to performance with the biggest damage done as you would expect on the tightest stops and shortest horizons where we lose up to 140 units of annualised SR. We're not going to be able to do much unless we assume we can get near the limit price on stop loss orders (*L*).
If we assume, reasonably conservatively, that we receive our limits on stop profit orders without benefitting from bid-ask bounce, but have to pay slippage on our stop losses - which is CLS - there are still two systems that survive with high positive SR.
Interactive brokers provides synthetic stop losses on some markets; whether it's better to use these or simulate our own stops by placing aggressive market orders once we are past the stop level is an open question.
Note that even the most optimistic of these (CSL2) sees us losing half or more of the pre-cost returns, again hardly what I usually like to see but I guess I could live with an annualised SR of over 7 :-)
All of the above assumes prices are a pure random walk.... but the original motivation was the fact that prices in the sort of region I'm looking at appear to be mean reverting. Which would radically improve the results above. It's easy to generate autocorrelated returns at the same frequency as your data, but I'm generating returns every 10 seconds whilst the autocorrelation is happening at a slower frequency. We'd have to use something like a brownian bridge to fill in the other returns, or also assume autocorrelation happens at the 10 second frequency, which we don't know for sure and would flatter us too much. The final problem is that I don't actually have figures to calibrate this with; the arvix paper doesn't measure autocorrelation.
Since I've already spent quite a lot of time digging into this, I decided not to bother. Ultimately a system like this can only really be tested by trading it; as that's also the only way to find out which of the assumptions about fill prices is closest to the truth. Since the SR ought to be quite high, we should be able to work out quite quickly if this is working or not.
System choice in tick terms
This then brings me back to which is the best option of H and K to trade.
Remember from above that the average R expressed in daily vol units varies between 0.10 (for H=120 seconds) up to 0.31 (H=900 seconds). If we use K=0.8 (with L=0.75) then we'll have a stop of 0.05R, which will be 0.05*0.10 = 0.005 times daily vol. To put that in context, if S&P 500 vol is around 1%, or call it 60 points a day, then R=6 price units, and our stop will be just 0.3 price points away.. which is just over one tick (0.25)! You can now see why the tight K, short horizon, systems were so sensitive to fill assumptions. For the slowest system in the second set of analysis above, H=300/K=.85, as a stop of 0.1R with R~0.17 we get up to four ticks between our take profit and stop loss limits.
We're then faced with the dilemna of hoping we can actually get filled within a tick of that level (and if it doesn't will absolutely bleed money), or slowing down to something that will definitely lose money unless we get mean reversion (but won't lose as much).
If we were to say we wanted to see at least 10 ticks between take profit and stop loss, then we're looking at something like H=900, K=0.87; or H=120, K=1; or somewhere in between. The former has a less bad SR, better skew and lower standard deviation - basically a tighter stop on a longer horizon is better than a looser stop on a shorter one.
Next steps
My plan then is to actually trade this, on the S&P with H=900 and K=0.87. I'll come back with a follow up post when I've done this!